
business continuity plan (BCP)
What is a business continuity plan (BCP)?
A business continuity plan (BCP) is a document that consists of the critical information an organization needs to continue operating during an unplanned event.
The BCP states the essential functions of the business, identifies which systems and processes must be sustained, and details how to maintain them. It should consider any possible business disruption.
A BCP covers risks including cyber attacks, pandemics, natural disasters and human error. The array of possible risks makes it vital for an organization to have a business continuity plan to preserve its health and reputation. A proper BCP decreases the chance of a costly power outage or IT outage.
IT administrators often create the plan. However, the executive staff participate in the process, providing knowledge of the company and oversight. They also ensure the BCP is regularly updated.
Importance of business continuity planning
Business continuity planning is a proactive business process that lets a company understand potential threats, vulnerabilities and weaknesses to its organization in times of crisis. The creation of a business continuity program ensures company leaders can react quickly and efficiently to business interruption.
A BCP enables a company to continue to serve customers during a crisis and minimize the likelihood of customers going to competitors. These plans decrease business downtime and outline the steps to be taken -- before, during and after an emergency -- to maintain the company's financial viability.
Elements of a business continuity plan
According to business continuity consultant Paul Kirvan, a BCP should contain the following items:
- initial data at the beginning of the plan, including important contact information;
- a revision management process that describes change management procedures;
- the purpose and scope;
- how to use the plan, including guidelines as to when the plan will be initiated;
- policy information;
- emergency response and management procedures;
- step-by-step procedures;
- checklists and flow diagrams;
- a glossary of terms used in the plan; and
- a schedule for reviewing, testing and updating the plan.
In the book Business Continuity and Disaster Recovery Planning for IT Professionals, Susan Snedaker recommends asking the following questions:
- How would the organization function if desktops, laptops, servers, email and internet access were unavailable?
- What single points of failure exist?
- What risk controls and risk management systems are in place?
- What are the critical outsourced relationships and dependencies?
- During a disruption, what workarounds are there for key business processes and internal functions, such as human resources?
- What is the minimum number of staff needed to run data center and other operations, and what functions would they need to carry out?
- What are the key skills, knowledge and expertise needed to recover?
- What critical security or operational controls are needed if computer systems are down?
Business continuity planning steps
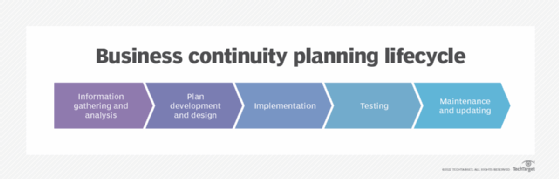
The business continuity planning lifecycle contains these five steps:
- Information gathering and analysis, featuring business impact analysis (BIA) and risk assessment (RA);
- plan development and design;
- implementation;
- testing; and
- maintenance and updating.
BCP implementation
Once the business has started the planning process, it launches the BIA and RA processes to collect important data. The BIA defines the critical functions that must continue during a crisis and the resources needed to maintain those operations. The RA details the potential internal and external risks and threats, the likelihood of them happening, and the possible damage they could cause.
The next step determines the best ways to deal with the risks and threats outlined in the BIA and RA, and how to limit damage from an event. A successful business continuity plan defines step-by-step procedures for response.
The BCP should not be overly complex and does not need to be hundreds of pages long; it should contain just the right amount of information to keep the business running. Small businesses can use a one-page plan with all the necessary details. That can be more helpful than a long plan that is difficult to use. Those details should include the following:
- minimum resources needed for business continuity;
- locations where that can take place;
- personnel needed to accomplish it; and
- potential costs.
Key implementation steps
The four steps involved in implementing a BCP are the following:
- Oversight. Decide who will oversee the plan. Ideally, a BCP committee will include business, security and IT leaders.
- Analysis. Conduct the BIA.
- Details. Answer business continuity questions, such as the following:
- Who will be affected by a business disruption?
- Who holds a hard copy of contact information for top customers and clients?
- How and when will customers, employees and management be notified?
- What are the alternative means of communication if phones go down?
- Which employees are needed for the restoration of critical business functions and how will they be reached or relocated?
- Which critical products and services should the company focus on restoring first?
- What issues must be addressed within the first 24 to 48 hours?
- Does every team and department have its own BCP? Who is in charge of each?
- What is the emergency succession plan for senior staff, including the CEO?
- Which employees will perform emergency tasks?
- Where will off-site crisis meetings take place?
- Who will interact with local emergency responders, such as firefighters and police?
- Who are the key vendors, including data backup providers?
- Action. Create a BCP that includes specific actions and assigned roles for each stage of the emergency, including the following:
- Initial response. This defines how the company will respond to the business interruption within the first hours. This is the period when team members are contacted and the BCP is activated.
- Relocation. During this stage, alternate facilities are activated and work-at-home policies implemented.
- Recovery. Once personnel and equipment have been relocated, the assessment of damage and monitoring of business recovery begins. The recovery strategy must consider the organization's recovery time objective, or RTO, which is the maximum time IT systems can be down after a failure, as well as its recovery point objective, or RPO, which is the maximum data loss the organization can tolerate.
- Restoration. Personnel return to the original workplace or an alternate site. The company undertakes infrastructure verification, documents the incident and reviews lessons learned.
BCP testing
An organization's technology, processes, staff and facilities constantly change. Therefore, regular testing, reviewing and updating of a BCP is critical. Plan testing should be undertaken using tabletop exercises, walk-throughs, practice crisis management communications and emergency enactments to test the viability of the plan and to see how employees and executives react under stress.
Regular testing and maintenance ensure the BCP is current and accurate. A simple test of a business continuity plan might involve talking through it. A complex test requires a full run-through of what will happen in the event of a business disruption.
The test can be planned in advance or it can be done spur of the moment to better simulate an unplanned event. If issues arise during testing, the plan should be corrected accordingly during the maintenance phase. Maintenance also includes a review of the critical functions outlined in the BIA and the risks described in the RA, as well as plan updating if necessary.
A business continuity plan must be continually improved; updates should not wait for a crisis. Staff members involved in the plan must get regular updates and business continuity training. An internal or external business continuity plan audit should be used to evaluate the effectiveness of the BCP and highlight areas for improvement.

For specific BCP testing steps, download the guide Business continuity and disaster recovery testing templates.
Business continuity planning software, tools and trends
There is help available to guide organizations through the business continuity planning process, from consultants to tools to full software. Which approach an organization should take depends on the complexity of the business continuity planning task, the amount of time and personnel available, and the budget. Before making a purchase, it is advisable to research both products and vendors, evaluate demos, and talk to other users.
For more complicated functions, business continuity planning software uses databases and modules for specific exercises. The U.S. Department of Homeland Security, through its Ready.gov website, offers software in its Business Continuity Planning Suite. Other business continuity software vendors include Castellan, formed from the merger of Assurance, Avalution and ClearView in 2020; CLDigital, formerly Continuity Logic; Fusion Risk Management; Quantivate; and Sungard Availability Services.
The Federal Financial Institutions Examination Council's Business Continuity Management booklet contains guidance on plan development, testing, standards and training for both financial and nonfinancial organizations.
Free download of BCP template
The role of the business continuity professional has changed and continues to evolve. As IT administrators are increasingly asked to do more with less, it is advisable for business continuity professionals to be well versed in technology, security, risk management, emergency management and strategic planning.
Business continuity planning must also take into account emerging and growing technologies, such as the cloud and virtualization, as well as new threats, such as cyber attacks like ransomware.
One resource that combines all these elements is SearchDisasterRecovery's free, downloadable business continuity plan template. It provides guidance and insight for creating a successful BCP.
Business continuity planning standards
Business continuity planning standards provide a starting point.
The International Organization for Standardization (ISO) 22301:2019 standard is regarded as the global standard for business continuity management. ISO 22301 is often complemented by other standards, such as the following:
- ISO 22313 guidance on the use of ISO 22301;
- ISO 22317 guidelines for business impact analysis;
- ISO 22318 continuity of supply chains;
- ISO 22398 exercise guidelines; and
- ISO 22399 incident preparedness and operational continuity management.
Other standards include the following:
- National Fire Protection Association 1600 emergency management and business continuity;
- National Institute of Standards and Technology SP 800-34 IT contingency planning; and
- British Standards Institution BS 25999 standard for business continuity.
Emergency management and disaster recovery plans
An emergency management plan is a document that helps to lessen the damage of a hazardous event. Proper business continuity planning includes emergency management as an important component. The appointed emergency management team takes the lead during a business disruption.
An emergency management plan, like a BCP, should be reviewed, tested and updated regularly. It should be fairly simple and provide the steps needed to get through an event. The plan also should be flexible, because situations are often fluid. Teams involved in the event of a disaster should communicate frequently during the incident.
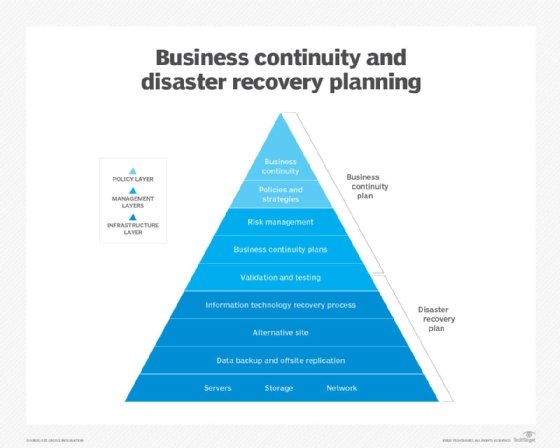
Disaster recovery (DR) and business continuity planning are often linked, but they are different. A DR plan is reactive, as it details how an organization recovers after a business disruption. A business continuity plan is a proactive approach that describes how an organization can maintain business operations during an emergency.
Learn more about responding to unplanned emergencies in this complete guide to managing crises.






