risk analysis
What is risk analysis?
Risk analysis is the process of identifying and analyzing potential issues that could negatively impact key business initiatives or projects. This process is done to help organizations avoid or mitigate those risks.
Performing a risk analysis includes considering the possibility of adverse events caused by either natural processes, such as severe storms, earthquakes or floods, or adverse events caused by malicious or inadvertent human activities. An important part of risk analysis is identifying the potential for harm from these events, as well as the likelihood of their occurrence.
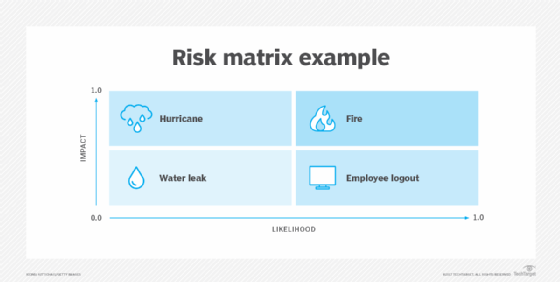
Why is risk analysis important?
Risk analysis provides a structured approach to assess uncertainties, enhancing an organization's adaptability and long-term success.
Enterprises and other organizations use risk analysis to do the following:
- Anticipate and reduce the effect of harmful results from adverse events.
- Evaluate whether the potential risks of a project are balanced by its benefits -- this aids in the decision-making process when evaluating whether to move forward with the project.
- Plan responses for technology or equipment failure or loss from adverse events, both natural and human-made.
- Identify the impact of and prepare for changes in the enterprise environment, including the likelihood of new competitors entering the market or changes to government regulatory policies.
- Allocate resources, such as time, money and employees, efficiently where they're most needed.
Types of risk analysis
Risk analysis comes in different forms, and organizations use various analysis tools, depending on their needs and requirements.
Companies typically use the following risk analysis methods:
- Risk-benefit analysis. Typically used for decision-making in the healthcare and environmental sectors, this type of risk analysis weighs the prospective benefits and risks of a choice or course of action. The main goal of this risk-benefit analysis is to make rational decisions by determining whether the potential benefits of a decision outweigh the potential risks, or vice versa.
- Business impact analysis (BIA). A BIA evaluates the possible effects of disruptions to crucial business processes. Organizations can use this study to determine which procedures are most crucial to their business operations and create backup plans to lessen the effects of disruptions and ensure business continuity in the wake of disasters.
- Needs assessment analysis. A needs assessment is a step-by-step method of determining what a business needs and where it's deficient or not doing so well. It helps leaders see where things could be improved and shows them how to use their resources to reach goals faster.
- Root cause analysis. A root cause analysis pinpoints the underlying reasons behind a specific problem, issue or undesirable outcome. While other risk analyses predict future events or possibilities, a root cause analysis focuses on uncovering the main causes behind the problems and understanding the effects of past and ongoing events.
What are the benefits of risk analysis?
Risk analysis offers organizations numerous benefits. Depending on the type and extent of the risk analysis, organizations can use the results to help them do the following:
- Minimize losses. Identifying, rating and comparing the overall impact of risks to the organization, in terms of both financial and organizational impacts, can help management preemptively create a risk plan.
- Strengthen security. Identifying potential gaps in security can help organizations determine the steps they need to take to eliminate the weaknesses and strengthen security.
- Mitigate risks. Putting security controls in place can help organizations mitigate the most important risks.
- Improve resource optimization. Prioritizing risks and allocating resources more effectively can help organizations address the most significant risks.
- Increase awareness. Creating awareness among employees, decision-makers and stakeholders about security measures and risks by highlighting best practices during the risk analysis process can aid organizations.
- Manage costs. Understanding the financial impact of potential security risks can help organizations develop cost-effective methods for implementing these information security policies and procedures.
Drawbacks of risk analysis
While risk analysis provides many benefits, it also comes with certain challenges that organizations should consider, including the following:
- Uncertain results. Since risk analysis is probabilistic in nature, it can never provide a precise and correct evaluation of risk exposure and could end up overlooking some risks. For instance, risk analysis is unable to forecast unforeseen, black swan events.
- Complexity. Risk analysis is often a complex procedure since detecting and evaluating all potential dangers requires considering a variety of risk factors.
- Time consumption. The preparation, collection and analysis of data for a complete risk analysis often requires a lot of time and effort.
- Overemphasis on analysis. Organizations that place an excessive amount of emphasis on the analysis might devote too much time assessing risks and not enough time taking steps to address them. Additionally, it could cause companies to divert resources from other, more profitable uses.
Steps in risk analysis process
An organization's health and safety strategy must include steps for risk assessment to ensure that it's prepared for a variety of risks.
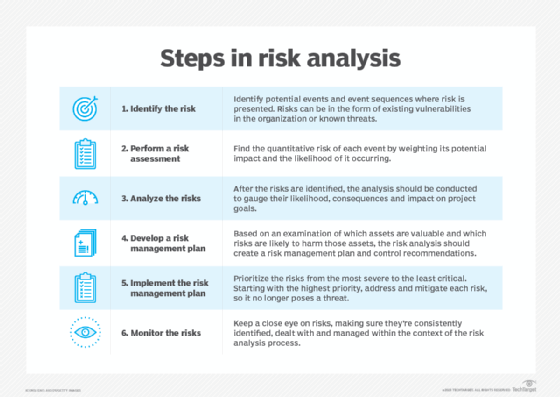
The risk analysis process usually follows these basic steps:
- Identify the risk. The reason for performing a risk assessment is to evaluate an IT system or other aspect of the organization to determine the risks to the software, hardware, data and IT employees. What are the possible adverse events that could occur, such as human error, fire, flooding or earthquakes? What is the potential that the integrity of the system will be compromised or that it won't be available?
- Perform a risk assessment. Getting input from management and department heads is critical to the risk assessment process. The risk assessment survey is a way to begin documenting specific risks or potential threats within each department.
- Analyze the risks. Once the risks are identified, the risk analysis process should determine the likelihood that each risk will occur, as well as the consequences linked to each risk and how they might affect the objectives of a project.
- Develop a risk management plan. Based on an analysis of which assets are valuable and which threats might affect those assets negatively, the risk analysis should produce a risk management plan and control recommendations that can be used to mitigate, transfer, accept or avoid the risk.
- Implement the risk management plan. The ultimate goal of risk assessment is to implement measures to remove or reduce the risks. Starting with the high-risk elements, resolve or at least mitigate each risk so it's no longer a threat.
- Monitor the risks. The ongoing process of identifying, treating and managing risks should be an important part of any risk analysis process.
The focus of the analysis, as well as the format of the results, can vary, depending on the type of risk analysis being carried out.
Qualitative vs. quantitative risk analysis
The two main approaches to risk analysis are qualitative and quantitative. Qualitative risk analysis typically means assessing the likelihood that a risk will occur based on subjective qualities and the impact it could have on an organization using predefined ranking scales. The impact of risks is often categorized into three levels: low, medium or high. The probability that a risk will occur can also be expressed the same way or categorized as the likelihood it will occur, ranging from 0% to 100%.
This article is part of
What is risk management and why is it important?
Quantitative risk analysis, on the other hand, uses numerical models and attempts to assign a specific financial amount to adverse events, representing the potential cost to an organization if that event occurs, as well as the likelihood that the event will occur in a given year. In other words, if the anticipated cost of a significant cyber attack is $10 million and the likelihood of the attack occurring during the current year is 10%, the cost of that risk would be $1 million for the current year.
A qualitative risk analysis produces subjective results because it gathers data from participants in the risk analysis process based on their perceptions of the probability of a risk and the risk's likely consequences. Categorizing risks in this way helps organizations, project teams and stakeholders decide which risks can be considered low priority and which must be actively managed to reduce the effect on the enterprise or the project.
A quantitative risk analysis, in contrast, examines the overall risk of a project and generally is conducted after a qualitative risk analysis. The quantitative risk analysis numerically analyzes the probability of each risk and its consequences.
The goal of a quantitative risk analysis is to associate a specific financial amount to each identified risk, representing the potential cost to an organization if that risk occurs. So, an organization that has done a quantitative risk analysis and is then hit with a data breach should be able to easily determine the financial impact of the incident on its operations.
A quantitative risk analysis provides an organization with more objective information and data than the qualitative analysis process, thus aiding in its value to the decision-making process.
Examples of risk analysis
Risk analyses are conducted for a variety of situations, but industry-specific examples are more helpful to leaders than generic ones. The following are risk analysis examples for the construction, manufacturing, and transport and logistics sectors:
- After receiving a project proposal for a luxury resort, the owner of the construction company conducted a risk analysis to uncover potential hazards, liabilities and risk mitigation strategies.
- A car manufacturing plant performs a risk analysis to examine potential hazards in the manufacturing process. This analysis pinpoints risks such as equipment failure and accidents, as well as evaluates their likelihood and potential consequences.
- An international shipping project being planned by a transport company involves a risk analysis for potential project hazards, such as shipping costs, product damage and delays. According to the study, the project is feasible, so the business decides to reduce risks by purchasing shipment insurance and increasing its contingency reserve.
Both risk assessments and threat modeling uniquely contribute to safeguarding systems and data for businesses. Discover the differences between the two approaches.







