
data masking

What is data masking?
Data masking is a method of creating a structurally similar but inauthentic version of an organization's data that can be used for purposes such as software testing and user training. The purpose is to protect the actual data while having a functional substitute for occasions when the real data is not required.
Although most organizations have stringent security controls in place to protect production data in storage and in business use, sometimes that same data element has been used for operations that are less secure. The issue is often compounded if these operations are outsourced and the organization has less control over the environment. In the wake of compliance legislation, most organizations are no longer comfortable exposing real data unnecessarily.
Data masking substitutes original values in a data set with randomized data using various data shuffling and manipulation techniques. The obfuscated data maintains the unique characteristics of the original data so that it yields the same results as the original data set.
How does data masking work?
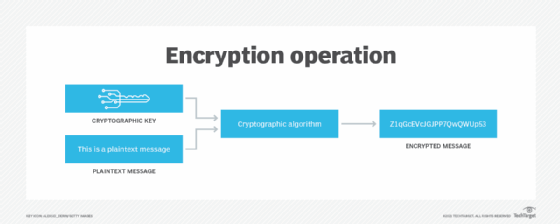
Encryption is the best way to securely store and transfer sensitive data. Unfortunately, encrypted data is difficult to query and analyze. For example, you cannot filter users based on age if their data of birth is encrypted. As a result, organizations need another way to keep data secure and private when it is being used for research, development and testing.
This article is part of
What is data security? The ultimate guide
Data masking, which is also called data sanitization, keeps sensitive information private by making it unrecognizable but still usable. This lets developers, researchers and analysts use a data set without exposing the data to any risk.
Data masking is different from encryption. Encrypted data can be decrypted and returned to its original state with the correct encryption key. With masked data, there is no algorithm to recover the original values. Masking generates a characteristically accurate but fictitious version of a data set that has zero value to hackers. It also cannot be reverse engineered, and statistical outputs cannot be used to identify individuals.
Like data encryption, not every data field needs to be masked, although some fields must be completely hidden.
Why is data masking important?
Various data protection standards and regulations require that businesses and other organizations protect personally identifiable information, or PII, and protected health information and keep it confidential. These standards and regulations include the following:
- California Consumer Privacy Act (CCPA)
- General Data Protection Regulation (GDPR)
- Health Insurance Portability and Accountability Act (HIPAA)
- Payment Card Industry Data Security Standard (PCI DSS)
These regulations and standards play an important role in establishing appropriate levels of data protection and preventing unauthorized users from accessing the data. However, they also make it challenging for companies that want to analyze or share their data with others. Data masking reduces the risks of sensitive data being exposed and lets enterprises comply with various standards and regulations while handling regulated data.
Data masking techniques
A variety of data management techniques can be used to mask or anonymize PII and other private and sensitive data depending on the data type. These masking methods include the following:
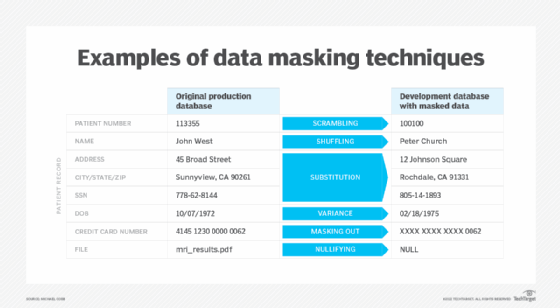
Scrambling
Scrambling randomly reorders alphanumeric characters to obscure the original content. For example, a customer complaint ticket number of 3429871 in a production environment could appear as 8840162 in a test environment after being scrambled. Although scrambling is easy to implement, it only works on certain types of data. Data obfuscated this way is not as secure as other techniques.
Substitution
This technique replaces the original data with another value from a supply of credible values. Lookup tables are often used to provide alternative values to the original, sensitive data. The values must pass rule constraints and preserve the original characteristics of the data.
It is harder to apply substitution than scrambling, but it can be applied to several data types and provides good security. For example, credit card numbers can be substituted with numbers that pass card provider validation rules.
Shuffling
Values within a column, such as user surnames, are shuffled to randomly reorder them. For example, if customer surnames are shuffled, the results look accurate but won't reveal any personal information. However, it is essential that the shuffling masking algorithm is kept secure so it cannot be used to reverse-engineer the data masking process.
Date aging
This method increases or decreases a date field by a specific date range. Again, the range value used must be kept secure.
Variance
A variance is applied to a number or date field. This approach is often used for masking financial and transaction value and date information. The variance algorithm modifies each number or date in a column by a random percentage of its real value. For instance, a column of employees' salaries could have a variance of plus or minus 5% applied to it. This would provide a reasonable disguise for the data while maintaining the range and distribution of salaries within existing limits.
Masking out
Masking out only scrambles part of a value and is commonly applied to credit card numbers where only the last four digits remain visible.
Nullifying
Nullifying replaces the real values in a data column with a null value, completely removing the data from view. Although this sort of deletion is simple to implement, the nullified column cannot be used in queries or analysis. As a result, it can degrade the integrity and quality of the data set for development and testing environments.
Types of data masking
The process of masking data can be initiated in different ways depending on where and when the data is needed. Various types of data masking include the following:
- Static data masking creates a separate masked data set from a production database that can be used in non-production environments, such as research, development and modelling. The masked data values must generate test and analytical results that mirror those of the original data and persist over time to ensure accurate and repeatable results.
- Dynamic data masking provides role-based security, particularly in production systems, when users require real data. In response to a request for data, dynamic masking transforms, obscures or blocks access to sensitive information fields in real-time based on the user's role. For example, when a financial call center operator handles a customer query, sensitive fields such as birth date, social security number and credit score will be masked unless the operator has the privileges required to view those fields. By streaming data from the production environment in response to a request, it avoids the need to store the masked data in a separate database. However, if the data is located across multiple systems, masking consistency can be an issue.
- On-the-fly data masking lets development teams read and mask a small subset of production data directly into a test environment. Data is masked as it is copied from one environment to another, so it is never present in an unmasked form in the target environment or the target database's transaction log. This approach eliminates delays incurred when a staging environment is used to prepare data. This makes it ideal for continuous software development environments.
Data masking challenges
There are several challenges involved with data masking:
Complicated. Data masking is not a simple, one-step activity. The data must be transformed to eliminate the risk of exposing sensitive information through inference attacks. At the same time, the system must maintain the complexity and unique characteristics of the original unmasked data, such as frequency distribution. This ensures that queries and analysis yield the same results as they would from the original.
Referential integrity. Masked data must maintain referential integrity across systems and databases. This is called deterministic data masking and ensures consistency of the masked output across databases and among servers, ensuring a value is always replaced with the same masked value. For example, the name "Helen" is always replaced by the value "Denise" wherever it occurs in the data being masked to preserve primary and foreign keys and relationships.
This may sound straightforward, but most databases are normalized for performance, and sensitive data gets stored in a variety of tables across one or more databases. Structured text, such as Extensible Markup Language (XML), can contain values that must be obfuscated, so they have to be parsed and masked.
Governance. For data used in software testing, the masking process must ensure data still matches internal rules governing the data attributes, such as zip codes or bank account numbers. If care is not taken here, the application will fail an update test because the data validation checks fail.
To overcome these challenges, database administrators must do a detailed review of the data being masked. Others involved with the data -- developers, testers, data scientists and security teams -- should contribute to the review. Input from these stakeholders ensures the appropriate masking techniques are used, data sources of valid replacement values are generated, referential integrity is maintained across all systems and the masked data maintains the characteristics of the original data.
Data masking best practices
Data masking is an important part of how organizations comply with privacy regulations and still are able to mine data for valuable insights. However, the ever-growing volume of structured and unstructured data that organizations collect has increased the complexity of data masking at scale. To remain compliant, it is essential to follow best practices:
- Organize and track. Enterprise data is spread across a variety of technologies and locations in different databases, tables and columns. To ensure the correct data is protected, it's important to locate and classify sensitive data that requires protection.
- Consider unstructured data. Images, PDFs, and XML- and text-based files must be protected. Images of items, such as passports, drivers licenses, receipts, checks and contracts, must be replaced with fake alternatives. Optical character recognition can be used to detect and mask sensitive content in files.
- Secure. Access given to masked data must comply with security policies related to roles, locations and permissions.
- Assess. Test the results of data masking techniques to ensure they provide the correct security level and that query results are comparable to those from the original data.
Data masking use cases
Data masking is used in many industries to drive innovation and improve services. For example, the banking and finance industries use it to develop and test new systems as well as improve fraud detection algorithms.
While data masking is used for different reasons, the main driver is data security and personal data privacy.
- Data breach prevention. Data obfuscation techniques are the main defense against data breaches. Even if a network's defenses fail to prevent an attacker exfiltrating sensitive data, if it is correctly masked or encrypted, the attackers won't be able to associate the data with individuals.
- Privacy by design. Implementing data masking as part of the application development, testing and analysis lifecycles lets important data be shared both internally and externally while remaining compliant with data privacy regulations.
- Role-based access control. Many tasks require access to some, but not all, of a subject's data attributes. Data masking ensures employees can perform their duties without seeing data they are not authorized to view.
- Faster, safer test data. Masked data retains the integrity and quality needed for testing without compromising the actual data. Automated data masking can be integrated with existing systems to remove time-consuming manual steps. This way, test data can be secured and released from a production environment quickly and without disruption. Data masking ensures production data is not exposed by more relaxed nonproduction environments or third-party developer access.

Many database vendors offer features and services that simplify data masking and integrate them with existing systems.
Find out more about keeping data safe beyond data masking in our comprehensive guide to data security.







