The 3 pillars of a DevSecOps model
In this excerpt from Chapter 1 of Securing DevOps: Security in the Cloud, author Julien Vehent describes three principles critical to the DevSecOps model.
The DevOps portmanteau means different things to different people. Broadly applied, the term relates to collaboration between development and operations. Since its inception, DevOps has spawned other initiatives, from WinOps to OpsDev to BizDevOps. But perhaps none is more important than DevSecOps, which sandwiches the always critical security aspect directly between development and operations.
The importance of security has never been denied, despite the fact that it is often overlooked or simply cast aside. As more employees, enterprises and consumers trust applications with their confidential data, it's a disservice not to consider security from the start. Yet, in a rush to meet these users' needs, DevOps teams are forgoing the security process in favor of getting a product to market more quickly. Organizational leaders are realizing it's time to adopt a DevSecOps model to put security back where it belongs in the application development process.
In this excerpt from Chapter 1 of Securing DevOps: Security in the Cloud, published by Manning Publications, author Julien Vehent outlines a continuous DevSecOps model that focuses on integrating strong security measures into the DevOps process. Read on to learn how development, security and operations teams need three DevSecOps principles -- test-driven security (TDS); monitoring and responding to attacks; and assessing risks and maturing security -- to achieve optimal security.
"A comprehensive security strategy mixes technology and people to identify areas of improvement and allocate resources appropriately, all in rapid improvement cycles," Vehent wrote. "This book aims to give you the tools you need to reach that level of maturity in your organization."
1.3.1 Test-driven security

The myth of attackers breaking through layers of firewalls or decoding encryption with their smartphones makes for great movies, but poor real-world examples. In most cases, attackers go for easy targets: web frameworks with security vulnerabilities, out-of-date systems, administration pages open to the internet with guessable passwords, and security credentials mistakenly leaked in open source code are all popular candidates.
Our first goal in implementing a continuous security strategy is to take care of the baseline: apply elementary sets of controls on the application and infrastructure of the organization and test them continuously. For example:
- SSH root login must be disabled on all systems.
- Systems and applications must be patched to the latest available version within 30 days of its release.
- Web applications must use HTTPS, never HTTP.
- Secrets and credentials must not be stored with application code, but handled separately in a vault accessible only to operators.
- Administration interfaces must be protected behind a VPN.
The list of security best practices should be established between the security team and the developers and operators to make sure everyone agrees on their value. A list of baseline requirements can be rapidly assembled by collecting those best practices and adding some common sense. In part 1 of the book, I talk about various steps in securing applications, infrastructure, and CI/CD pipelines.
Application security
Modern web applications are exposed to a wide range of attacks. The Open Web Application Security Project (OWASP) ranks the most common attacks in a top-10 list published every three years: cross-site scripting, SQL injections, cross-site request forgery, brute-force attacks, and so on, seemingly endlessly. Thankfully, each attack vector can be covered using the right security controls in the right places. In chapter 3, which covers application security, we'll take a closer look at the controls a DevOps team should implement to keep web applications safe.
Infrastructure security
Relying on IaaS to run software doesn't exempt a DevOps team from caring about infrastructure security. All systems have entry points that grant elevated privileges, like VPNs, SSH gateways, or administration panels. When an organization grows, special care must be taken to continuously protect the systems and networks while opening new accesses and integrating more pieces together.
Pipeline security
The DevOps way of shipping products through automation is vastly different from traditional operations most security teams are used to. Compromising a CI/CD pipeline can grant an attacker full control over the software that runs in production. Securing the automated steps taken to deliver code to production systems can be done using integrity controls like commit or container signing. I'll explain how to add trust to the CI/CD pipeline and guarantee the integrity of the code that runs in production.
Testing continuously
In each of the three areas I just defined, the security controls implemented remain fairly simple to apply in isolation. The difficulty comes from testing and implementing them everywhere and all the time. This is where test-driven security comes in. TDS is a similar approach to test-driven development (TDD), which recommends developers write tests that represent the desired behavior first, and then write the code that implements the tests. TDS proposes to write security tests first, representing the expected state, and then implement the controls that pass the tests.
In a traditional environment, implementing TDS is difficult because tests must run on systems that live for years. But in DevOps, every change to the software or infrastructure goes through the CI/CD pipeline and is a perfect place to implement TDS, as shown in figure 1.5.
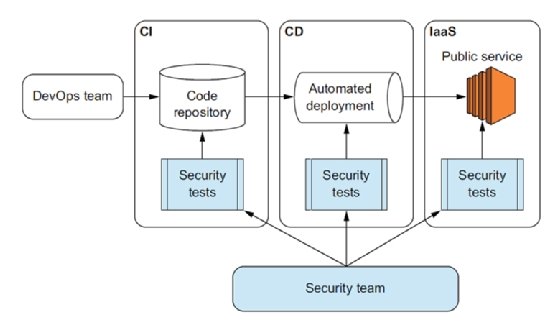
The TDS approach brings several benefits:
- Writing tests forces security engineers to clarify and document expectations. Engineers can build products with the full knowledge of the required controls rather than catching up post-implementation.
- Controls must be small, specific units that are easy to test. Vague requirements such as "encrypt network communication" are avoided; instead, we use the explicit "enforce HTTPS with ciphers X, Y, and Z on all traffic," which clearly states what's expected.
- Reusability of the tests across products is high, as most products and services share the same base infrastructure. Once a set of baseline tests is written, the security team can focus on more-complex tasks.
- Missing security controls are detected prior to deployment, giving developers and operators an opportunity to fix the issues before putting customers at risk.
Tests in the TDS approach will fail initially. This is expected to verify their correctness once they pass, after the feature is implemented. At first, security teams should help developers and operators implement controls in their software and infrastructure, taking each test one by one and providing guidance on implementation, and eventually transferring ownership of the tests to the DevOps teams. When a test passes, the teams are confident the control is implemented correctly, and the test should never fail again.
An important part of TDS is to treat security as a feature of the product. This is achieved by implementing controls directly into the code or the systems of the product. Security teams that build security outside of the applications and infrastructure will likely instigate a culture of distrust. We should shy away from this approach. Not only does it create tensions between teams, it also provides poor security as controls aren't aware of the exact behavior of the application and miss things. A security strategy that isn't owned by the engineering teams won't survive for long and will slowly degrade over time. It's critical for the security team to define, implement, and test, but it's equally critical to delegate ownership of key components to the right people.
TDS adopts the DevOps principles of automating the pipeline and working closely with teams. It forces security folks to build and test security controls within the environments adopted by developers and operators, instead of building their own separate security infrastructure. Covering the security basics via TDS significantly reduces the risk of a service getting breached but doesn't remove the need for monitoring production environments.
Securing DevOps: Security in the Cloud
Click here to learn more about Securing DevOps: Security in the Cloud. Enter "TechTarget 40" at checkout and receive a 40% discount on this title.
Download a PDF of chapter 1.
Learn more about Manning Publications.
1.3.2 Monitoring and responding to attacks
When security engineers get bored, we like to play games. A popular game we used to play in the mid-2000s was to install a virtual machine with Windows XP completely unpatched, plug it directly into the internet (no firewall, no antivirus, no proxy), and wait. Can you guess how long it took for it to get hacked?
Scanners operated by malware makers would detect the system in no time and send one of the many exploit codes Windows XP was vulnerable to. Within hours, the system was breached and a backdoor was opened to invite more viruses to contaminate the system. It was fun to watch, but more importantly, it helped teach an important lesson: all systems connected to the internet will eventually get attacked--there are no exceptions.
Operating a popular service on the public internet is, in essence, similar to our Windows XP experiment: at some point, a scanner will pick it up and attempt to break in. The attack might target specific users and try to guess their passwords, it might take the service down and ask for a ransom, or it might exploit a vulnerability in the infrastructure to reach the data layer and extract information.
Modern organizations are complex enough that covering every angle at a reasonable cost is often not possible. Security teams must pick priorities. Our approach to monitoring and responding to attacks focuses on three areas:
- Logging and fraud detection
- Detecting intrusions
- Responding to incidents
Organizations that can achieve these three items are prepared to face a security incident. Let's take a high-level view of each of these phases.
Logging and detecting fraud
Generating, storing, and analyzing logs are areas that serve every part of the organization. Developers and operators need logs to track the health of services. Product managers use them to measure the popularity of features or retention of users. With regards to security, we focus on two specific needs:
- Detecting security anomalies
- Providing forensic capabilities when incidents are being investigated
Although ideal, log collection and analysis is rarely possible. The sheer amount of data makes storing them impractical. In part 2 of this book, I talk about how to select logs for security analysis and focus our efforts on specific parts of the DevOps pipeline.
We'll explore the concept of a logging pipeline to process and centralize log events from various sources. Logging pipelines are powerful because they provide a single tunnel where anomaly detection can be performed. It's a simpler model than asking each component to perform detection themselves but can be difficult to implement in a large environment. Figure 1.6 shows an overview of the core components of a logging pipeline, which I cover in detail in chapter 7. It has five layers:
- A collection layer to record log events from various components of the infrastructure
- A streaming layer to capture and route the log events
- An analysis layer to inspect the content of logs, detect fraud, and raise alerts
- A storage layer to archive logs
- An access layer to allow operators and developers to access logs
A powerful logging pipeline gives a security team the core functionalities it needs to keep an eye on the infrastructure. In chapter 8, I talk about how to build a solid analysis layer in the logging pipeline and demonstrate various techniques that are useful for monitoring systems and applications. It will set the foundations that we need to work on intrusion detection in chapter 9.

Detecting intrusions
When breaking into an infrastructure, attackers typically follow these four steps:
- Drop a payload on the target servers. The payload is some kind of backdoor script or malware small enough to be downloaded and executed without attracting attention.
- Once deployed, the backdoor contacts the mother ship to receive further instructions using a command-and-control (C2) channel. C2 channels can take the form of an outbound IRC connection, HTML pages that contain special keywords hidden in the body of the page, or DNS requests with commands embedded in TXT records.
- The backdoor applies the instructions and attempts to move laterally inside the network, scanning and breaking into other hosts until it finds a valuable target.
- When a target is found, its data must be exfiltrated, possibly through a channel parallel to the C2 channel.
In chapter 9, I explain how every single one of these steps can be detected by a vigilant security team. Our focus will be on watching and analyzing network traffic and system events using these security tools:
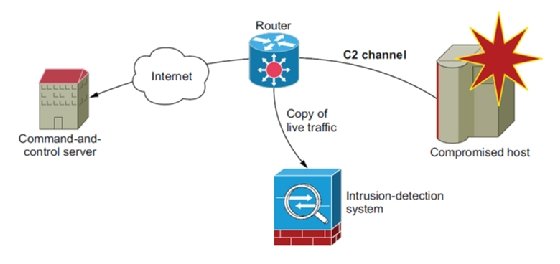
- Intrusion detection system (IDS) -- Figure 1.7 shows how an IDS can detect a C2 channel by continuously analyzing a copy of the network traffic and applying complex logic to network connections to detect fraudulent activity. IDSs are great at inspecting gigabytes of network traffic in real time for patterns of fraudulent activity and, as such, have gained the trust of many security teams. We explore how to use them in an IaaS environment.
![Using an IDS in a DevSecOps model]()
Figure 1.7. Intrusion detection systems can detect compromised hosts calling home by finding patterns of fraudulent activity and applying statistical analysis to outbound traffic. - Connection auditing -- Analyzing the entire network traffic going through an infrastructure isn't always a realistic approach. NetFlow provides an alternative to audit network connections by logging them into the pipeline. NetFlow is a great way to audit the activity of the network layer in an IaaS environment when low-level access isn't available.
- System auditing -- Auditing the integrity of live systems is an excellent way to keep track of what's happening across the infrastructure. On Linux, the audit subsystem of the kernel can log system calls performed on a system. Attackers often trip on this type of logging when breaching systems, and sending audit events into the logging pipeline can help detect intrusions.
Detecting intrusions is difficult and often requires security and operations teams to work closely together. When done wrong, these systems can consume resources that should be dedicated to operating production services. You'll see how a progressive and conservative approach to intrusion detection helps integrate it into DevOps effectively.
Incident response
Perhaps the most stressful situation any organization can find itself in is dealing with a security breach. Security incidents create chaos and bring uncertainty that can severely damage the health of even the most stable companies. As engineering teams scramble to recover the integrity of their systems and applications, leadership must deal with damage control and ensure the business will return to normal operations as quickly as possible.
In chapter 10, I introduce the six-phases playbook organizations should follow when reacting to a security incident. They are as follows:
- Preparation -- Make sure you have the bare minimum processes to deal with an incident.
- Identification -- Decide quickly whether an anomaly is a security incident.
- Containment -- Prevent the breach from going any further.
- Eradication -- Remove threats from the organization.
- Recovery -- Bring the organization back to normal operations.
- Lessons learned -- Revisit the incident after the fact to learn from it.
Every security breach is different, and organizations react to them in specific ways, making it difficult to generalize actionable advice to the reader. In chapter 10, we'll approach incident response as a case study to demonstrate how a typical company goes through this disruptive process, while using DevOps techniques as much as possible.
1.3.3 Assessing risks and maturing security
A complete continuous-security strategy goes beyond the technical aspects of implementing security controls and responding to incidents. Although present throughout the book, the "people" aspect of continuous security is the most critical when approaching risk management.
Assessing risks
For many engineers and managers, risk management is about making large spreadsheets with colored boxes that pile up in our inbox. This is, unfortunately, too often the case and has led many organizations to shy away from risk management. In part 3 of this book, I talk about how to break away from this pattern and bring lean and efficient risk management to a DevOps organization.
Managing risk is about identifying and prioritizing issues that threaten survival and growth. Colored boxes in spreadsheets can indeed help, but they're not the main point. A good risk-management approach must reach three targets:
- Run in small iterations, often and quickly. Software and infrastructure change constantly, and an organization must be able to discuss risks without involving weeks of procedures.
- Automate! This is DevOps, and doing things by hand should be the exception, not the rule.
- Require everyone in the organization to take part in risk discussions. Making secure products and maintaining security is a team effort.
A risk-management framework that achieves all three of these targets is presented in chapter 11. When implemented properly, it can be a real asset to an organization and become a core component of the product lifecycle that everyone in the organization welcomes and seeks.
Security testing
Another core strength of a mature security program is the ability to evaluate how well it's doing on a regular basis through security testing. In chapter 12, we'll examine three important areas of a successful testing strategy that help mature the security of an organization:
- Evaluating the security of applications and infrastructure internally, using security techniques like vulnerability scanning, fuzzing, static code analysis, or configuration auditing. We'll discuss various techniques that can be integrated in a CI/CD pipeline and become part of the software development lifecycle (SDLC) of a DevOps strategy.
- Using external firms to audit the security of core services. When targeted properly, security audits bring a lot of value to an organization and help bring fresh ideas and new perspectives to a security program. We'll discuss how to use external audit and "red teams" efficiently and make the best use of their involvement.
- Establishing a bug bounty program. DevOps organizations often embrace open source and publish large amounts of their source code publicly. These are great resources for independent security researchers that, in exchange for a few thousand dollars, will perform testing of your applications and report security findings to you.
Maturing a continuous security program takes years, but the effort leads security teams to become an integral part of the product strategy of an organization. In chapter 13, we'll end this book with a discussion on how to implement a successful security program over a period of three years. Through close collaboration across teams, good handling of security incidents, and technical guidance, security teams acquire the trust they need from their peers to keep customers safe. At its core, a successful continuous security strategy is about bringing security people, with their tools and knowledge, as close as possible to the rest of DevOps.
About the author
 Julien Vehent
Julien Vehent
Julien Vehent is the leader of security architecture for Mozilla's Cloud Services division. He is responsible for defining, implementing and operating the security of web services that millions of Firefox users interact with daily. Vehent consults with development and operations teams on risks and security and helps integrate controls in their build pipeline.
Vehent has been focusing on developing, operating and securing internet services for the past 15 years, starting as a Linux sys admin and graduating with a master's degree in information security in 2007. He gained experience in the financial sector in France, working on the customer portals of various French banks, then in startups in the U.S. before joining Mozilla in 2013.
He is a programmer and author of security tools, started in C and released Honeybrid, a honeypot proxy, back in 2007. In 2012, Vehent wrote AFW, an automated firewall that generates host-based rules within a Chef managed environment. At Mozilla, he wrote Cipherscan (TLS auditing), Mozilla InvestiGator (distributed digital forensics), SOPS (secrets encryption), Userplex (identity management) and many smaller tools to automate security in the organization.
Vehent also studied the Kaizen approach and observed Agile transform into DevOps and Kanban. The benefits of these methods on the productivity of both chemical and software industries forged his interest in evolving the information security community toward faster improvement cycles.







