buffer overflow

What is a buffer overflow?
A buffer overflow occurs when a program or process attempts to write more data to a fixed-length block of memory, or buffer, than the buffer is allocated to hold. Buffers contain a defined amount of data; any extra data will overwrite data values in memory addresses adjacent to the destination buffer. That sort of overflow can be avoided if the program includes sufficient bounds checking to flag or discard data when too much is sent to a memory buffer.
What is a buffer overflow attack and how does one work?
Exploiting a buffer overflow allows an attacker to control or crash a process or to modify its internal variables. Buffer overflow always ranks high in the Common Weakness Enumeration (CWE) and SANS Top 25 Most Dangerous Software Errors. A classic buffer overflow is specified as CWE-120 in the CWE dictionary of weakness types. Despite being well understood, buffer overflows continue to plague software from vendors both large and small.
A buffer overflow can occur inadvertently or when a malicious actor causes it. A threat actor can send carefully crafted input -- referred to as arbitrary code -- to a program. The program attempts to store the input in a buffer that isn't large enough for the input. If the excess data is then written to the adjacent memory, it overwrites any data already there.
The original data in the buffer includes the exploited function's return pointer -- the address to which the process should go next. However, the attacker can set new values to point to an address of their choosing. The attacker usually sets the new values to a location where the exploit payload is positioned. This change alters the process's execution path and transfers control to the attacker's malicious code.
For example, suppose a program is waiting for users to enter their name. Rather than enter the name, the hacker would enter an executable command that exceeds the stack size. The command is usually something short. For instance, in a Linux environment, the command is typically EXEC("sh"), which tells the system to open a command prompt window, known as a root shell in Linux circles.
Yet, overflowing the buffer with an executable command doesn't mean that the command will be executed. The attacker must specify a return address that points to the malicious command. The program partially crashes because the stack overflowed. It then tries to recover by going to the return address, but the return address has been changed to point to the command the hacker specified. The hacker must know the address where the malicious command will reside.
To get around needing the actual address, the malicious command is often padded on both sides by NOP -- or no operation -- computer instructions, a type of pointer. Padding on both sides is a technique used when the exact memory range is unknown. If the address the hacker specifies falls anywhere within the padding, the malicious command will be executed.
Programming languages like C and C++ have no protection against accessing or overwriting data in any part of their memory. As a result, they are vulnerable to buffer overload attacks. Bad actors can perform direct memory manipulation with common programming constructs.
Modern programming languages like C#, Java and Perl reduce the chance of coding errors creating buffer overflow vulnerabilities. Nevertheless, buffer overflows can happen in any programming environment where direct memory manipulation is allowed, whether through flaws in the program compiler, runtime libraries or features of the language itself.
Types of buffer overflow attacks
Techniques to exploit buffer overflow vulnerabilities vary based on the operating system (OS) and programming language. However, the goal is always to manipulate a computer's memory to subvert or control program execution.
Buffer overflows are categorized according to the location of the buffer in the process memory. They are mostly stack-based overflows or heap-based overflows. Both reside in a device's random access memory.
Some types of buffer overflow attacks include the following.
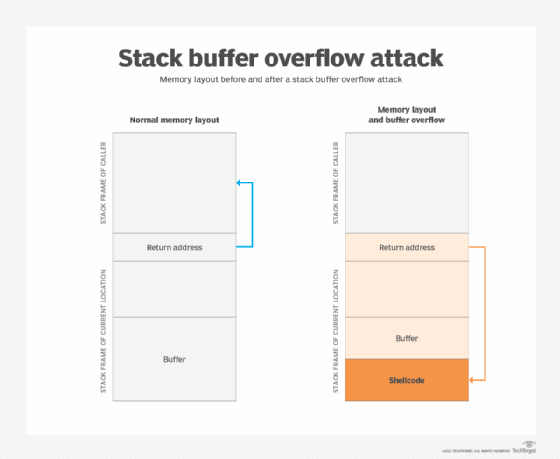
Stack-based buffer overflow or stack buffer overrun attack
The stack holds data in a last-in, first-out structure. It is a continuous space in memory used to organize data associated with function calls, including function parameters, function local variables and management information, such as frame and instruction pointers. Normally, the stack is empty until the targeted program requires user input, like a username or password. At that point, the program writes a return memory address to the stack, and then the user's input is placed on top of it. When the stack is processed, the user's input gets sent to the return address specified by the program.
However, a stack has a finite size. The programmer who develops the code must reserve a specific amount of space for the stack. If the user's input is longer than the amount of space reserved for it within the stack and the program does not verify that the input will fit, then the stack will overflow. This in itself isn't a huge problem, but it becomes a huge security hole when it is combined with malicious input.
Heap-based buffer overflow attack
The heap is a memory structure used to manage dynamic memory. Programmers often use the heap to allocate memory whose size is not known at compile time, where the amount of memory required is too large to fit on the stack or the memory is intended to be used across function calls. Heap-based attacks flood the memory space reserved for a program or process. Heap-based vulnerabilities, like the zero-day bug discovered in Google Chrome earlier this year, are difficult to exploit, so they are rarer than stack attacks.
Integer overflow attack
Most programming languages define maximum sizes for integers. When those sizes are exceeded, the result may cause an error, or it may return an incorrect result within the integer length limit. An integer overflow attack can occur when an integer is used in an arithmetic operation and the result of the calculation is a value in excess of the maximum size of the integer. For example, 8 bits of memory are required to store the number 192. If the process adds 64 to this number, the answer 256 will not fit in the allocated memory, as it requires 9 bits.
Format strings attack
Attackers change the way an application flows by misusing string formatting library functions, like printf and sprintf, to access and manipulate other memory spaces.
Unicode overflow attacks
These attacks exploit the greater memory required to store a string in Unicode format than in American Standard Code for Information Interchange (ASCII) characters. They can be used against programs that are expecting all input to be ASCII characters.
How to prevent buffer overflow attacks
There are several ways to prevent buffer overflow attacks from happening, including the following five:
- Use OS runtime protections. Most OSes use runtime protection, such as the following, to make it harder for overflow buffer attacks to succeed:
- Address space layout randomization, or ASLR, randomly arranges the address space positions of key data areas of a process. This includes the base of the executable and the positions of the stack, heap and libraries. This approach makes it difficult for an attacker to reliably jump to a particular function in memory.
- Data Execution Prevention marks areas of memory as either executable or nonexecutable. This prevents an attacker from being able to execute instructions written to a data area via a buffer overflow.
- Structured Exception Handling Overwrite Protection is designed to block attacks that use the Structured Exception Handler overwrite technique, which involves using a stack-based buffer overflow.
- Keep devices patched. Vendors issue software patches and updates to fix buffer overflow vulnerabilities that have been discovered. There is still a period of risk between the vulnerability being discovered and the patch being created and deployed.
- Follow the principle of least privilege (POLP). Users and applications should only be given the permissions they need to do their jobs or perform the tasks they are assigned. Following a POLP approach reduces the potential a buffer overflow attack occurs. In the stack overflow attack example above, the command prompt window that has been opened is running with the same set of permissions as the application that was compromised; the fewer privileges it has, the fewer the attacker will have. When possible, only grant temporary privileges to users and applications, and drop them once the task has been completed.
- Use memory safe programming languages. The most common reason why buffer overflow attacks work is because applications fail to manage memory allocations and validate input from the client or other processes. Applications developed in C or C++ should avoid dangerous standard library functions that are not bounds-checked, such as gets, scanf and strcpy. Instead, they should use libraries or classes that were designed to securely perform string and other memory operations. Better still, use a programming language that reduces the chances of a buffer overflow, such as Java, Python or C#.
- Validate data. Mobile and web applications developed in-house should always validate any user input and data from untrusted sources to ensure they are within the bounds of what is expected and to prevent overly long input values. Every application security policy should require vulnerability testing for potential input validation and buffer overflow vulnerabilities prior to deployment.






